

How Chrome Crushed My Dreams of Multilingual Word Game Dominance
Thu, Oct 5, 2023
Aw, Snap! I was feeling great. I had just announced my bilingual word game, Bilingdle, on social media, and the immediate response was overwhelmingly positive, especially among my friends and family on Facebook.
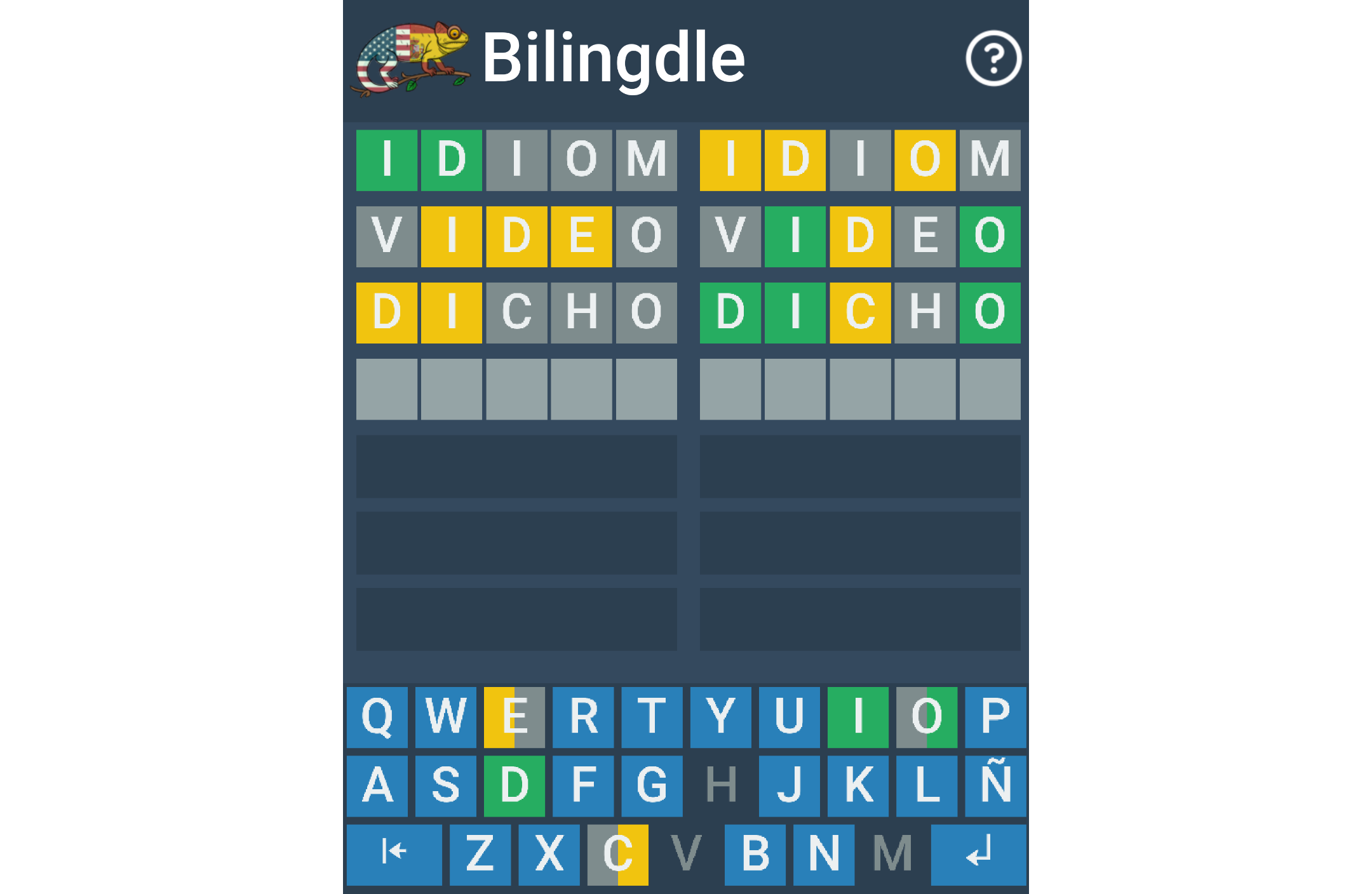
Tue, Sep 19, 2023
I first learned about Wordle in early 2022, and like so many others, I started to play daily. Eventually I discovered Quordle, which is like Wordle but with 4 words at the same time, and that became my daily game.
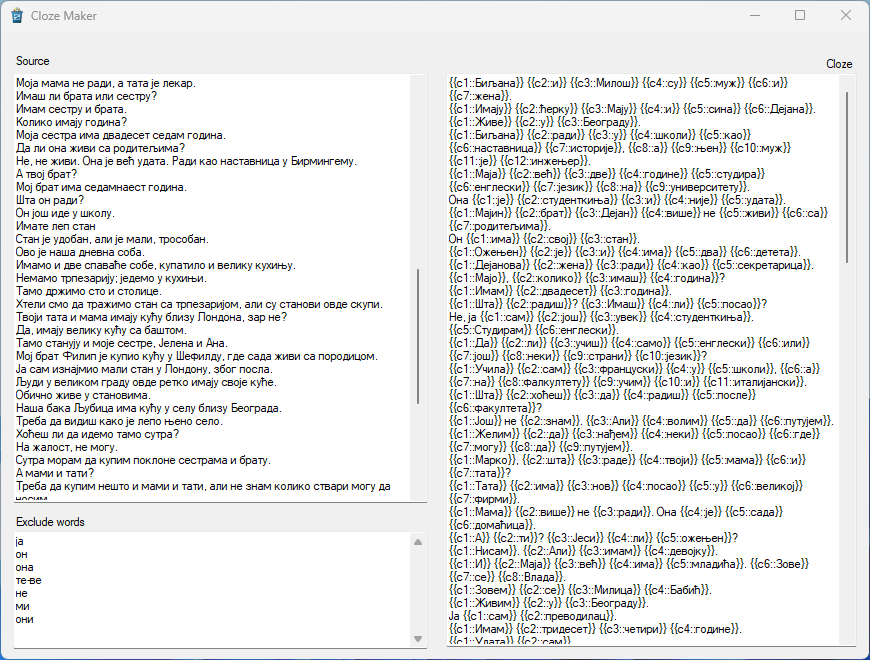
Fri, Jun 30, 2023
ClozeMaker is a small Windows application I threw together in 2017 to make the process of making cloze-deletion flashcards in Anki easier.
Mon, Jun 26, 2023
In 2014, I wrote a quick static site to help speed up the process of making flashcards in the way suggested by Gabriel Wyner in his book Fluent Forever.
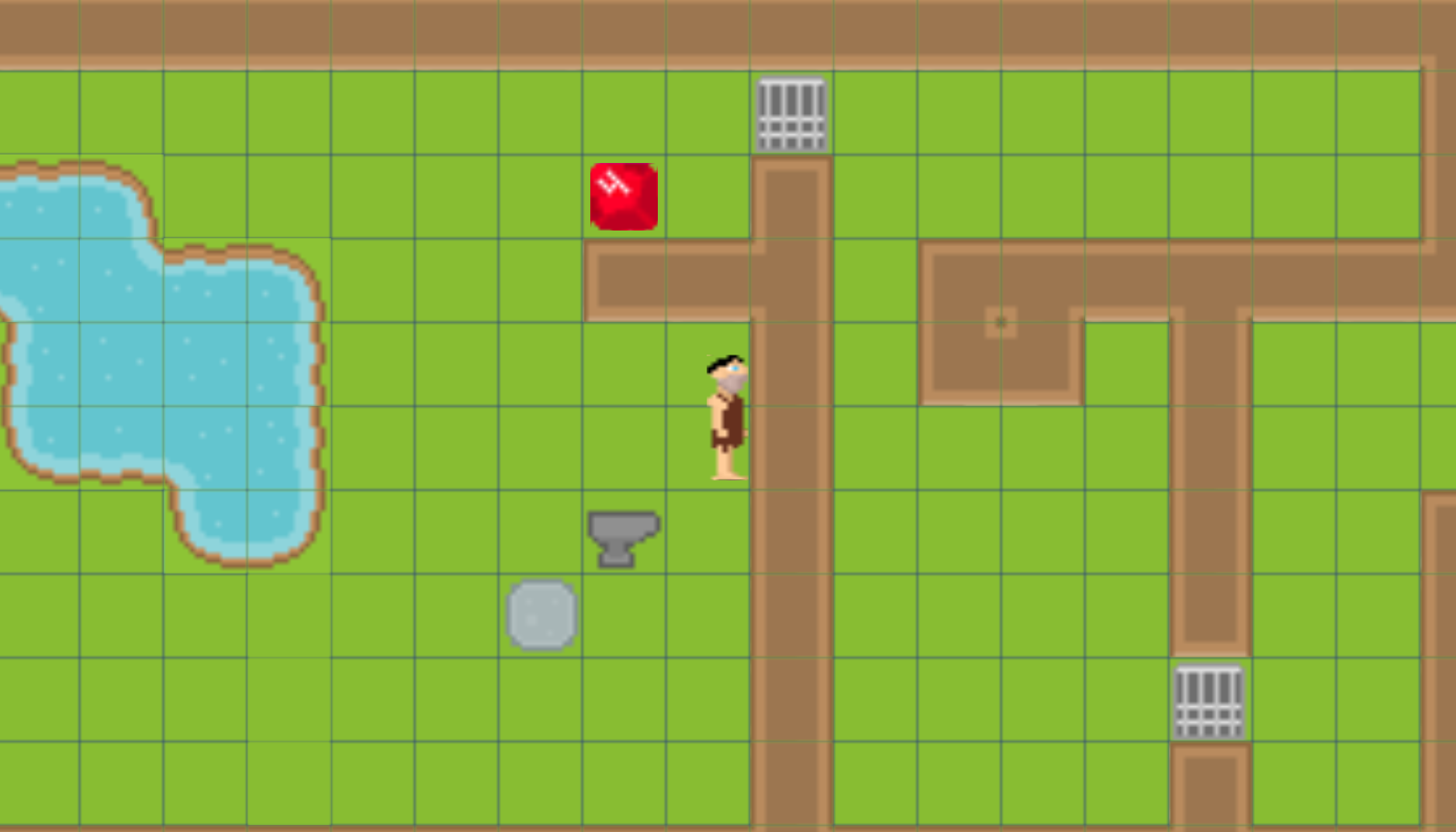
Fri, Jun 2, 2023
The GMTK Game Jam happened once again in July 2022, and like the previous year, Thomas and I decided to participate.

Thu, Jun 1, 2023
In June 2021, my frequent co-conspirator Thomas sent me a message asking I wanted to participate in a game jam that weekend.
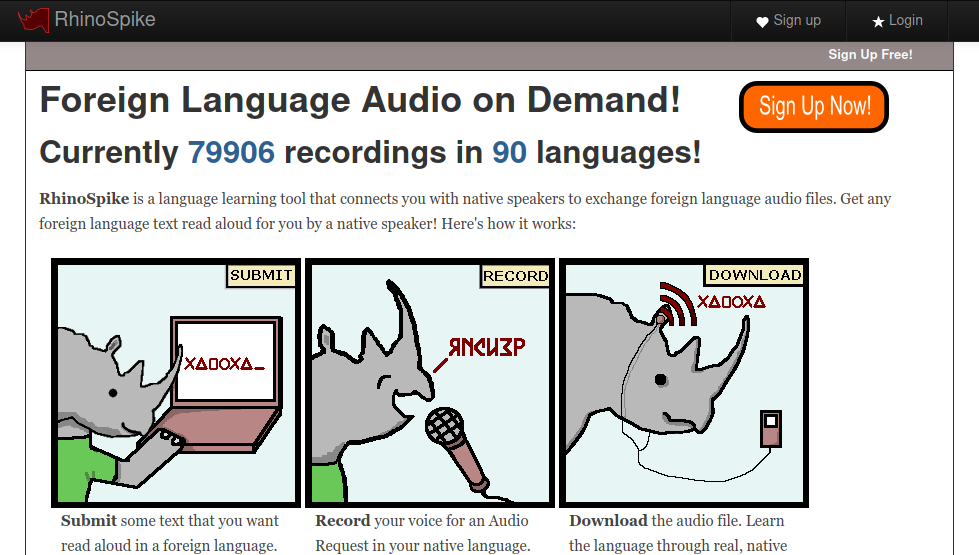
Thu, May 18, 2023
RhinoSpike is a site that allows language learners to get recorded audio in their target language. The audio is submitted by other users of the site who are native speakers of that language, and usually are also learning another language and seeking recording audio in their target language.

Tue, Dec 27, 2022
Babelhut was a blog created by my friend Thomas and myself to document our language learning journey online. Our about page from the site said this:
Fri, Apr 29, 2016
This page contains files and links referred to in my Polyglot Gathering 2016 presentation.
Video of the presentation Slides View my slides on Google Docs
What to do when Chrome mysteriously crashes the X.org server
Thu, Mar 13, 2014
This is largely a note to myself, to find later. This has already happened to me several times and I forget how to resolve this every time.
Reading with Interlinear Books
Tue, Mar 11, 2014
This post was originally posted on Babelhut.
Linas Vaštakas is an avid language learning enthusiast, and he currently runs a project InterlinearBooks.
Anki 2.0, Esperanto, and GitHub
Tue, Apr 24, 2012
Recently, I had become aware that Anki 2.0 was in beta through my friend Tom, who is working on making some changes to the MCD Support plugin so that it supports languages like Spanish as well as it does Japanese.